字符編碼:從基礎到亂碼解決
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
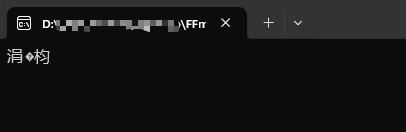
問題的引入#在日常開發中,當我們嘗試將中文輸出到控制臺時,點擊編譯。這時,細心的讀者可能會關注到 VS 的控制臺會輸出一段這樣的警告(也有可能是團隊規定不允許有警告出現??):
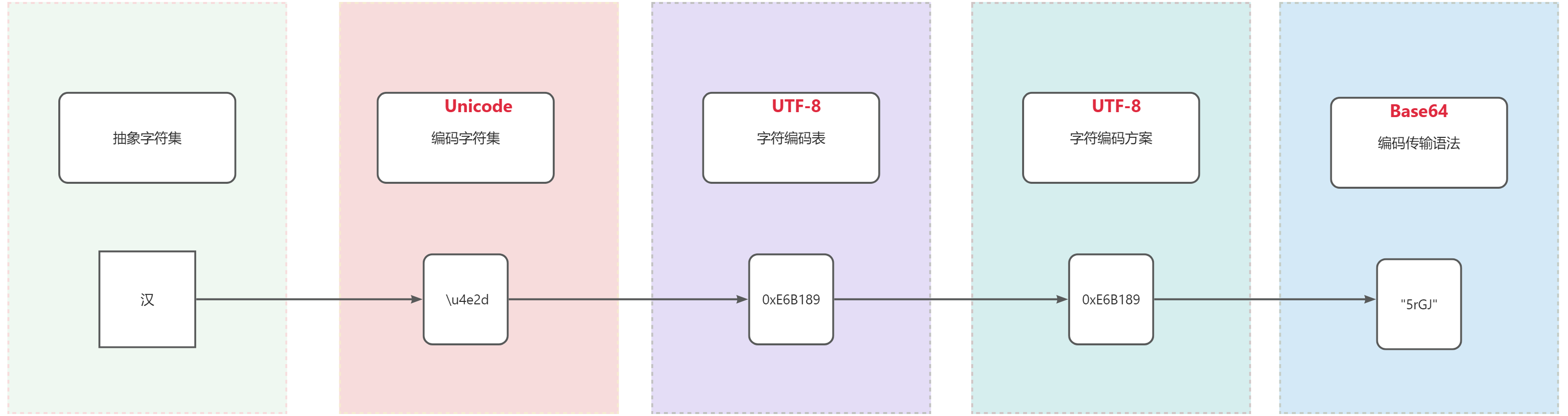
同時你心心念念的中文,輸出到控制臺卻成為了亂碼。為什么會出現這種問題呢? 這一系列的問題,歸根結底,就是一個字符在計算機中,應該怎么樣來表示。也就是字符的編碼問題。所以,讓我們先來了解了解,現代計算機體系中的編碼模型是什么樣的。 這一系列問題,追根溯源,其實就是一個字符在計算機中該如何表示的問題,即字符的編碼問題。那么,我們先來了解一下現代計算機體系中的編碼模型是怎樣的。 字符編碼模型#Unicode 字符編碼結構模型分為 5 層,下面我們以一個“漢”字為例,為大家介紹這 5 層。 抽象字符集 (Abstract Character Set) ACR#待編碼字符集,定義字符的邏輯集合,不涉及具體的編碼邏輯。這一層僅確定“漢”字屬于某個字符集。(像 GB2312 就只收錄了 6763 個常用的漢字和字符,一些生僻字就沒有被收錄進來。又比如 ASCII 中就沒有中文字符。) 編碼字符集 (Coding Character Set) CCS從抽象字符集(ACR)映射到一組非負整數,也就是為每一個字符分配一個唯一的二數字(碼位/碼點)。例如:Unicode、ASCII、USC、GBK等編碼。 在 Unicode 中,“漢”,表示成:\u6C49,而在 GBK 中,“漢”,表示成:0xBABA。 字符編碼表 (Character Encoding Form) CEF一個從一組非負整數(來自 CCS)到一組特定寬度代碼單元序列的映射。我們常說的 UTF-8、UTF-16、UTF-32 就是一個字符編碼表。他規定了在抽象字符集中的“非負整數”怎么用字節表示。 例如在 UTF-8 中,“漢”字用三個字節表示:0xE6B189。 字符編碼方案 (Character Encoding Scheme) CES一個從一組代碼單元序列(來自一個或多個 CEF)到序列化字節序列的映射。 定義碼元序列的存儲方式,解決字節序等問題: 例如:
此層確保不同系統對同一編碼單元序列的解析一致性。 傳輸編碼語法 (Transfer Encoding Syntax) TES針對特殊場景的二次編碼,如網絡傳輸:
通過上面的介紹,相信你對現代編碼模型的五層有了基本的了解。感興趣的讀者可以去看 Unicode technical report #17。 講完了字符編碼模型,接下來我們來了解一些常見的字符編碼標準及其特點。 常見字符編碼相信大家在日常的開發中,經常聽到 Unicode、GB2312、GBK、UTF-8、UTF-16、UTF-32、ANSI,卻又對這些概念比較模糊。首先要明確一點的是,Unicode、GB2312、GBK 都是編碼字符集,而UTF-8、UTF-16、UTF-32 則是 Unicode 的編碼字符表。ANSI 比較特殊,我們待會再具體介紹。 由于篇幅限制,對各個編碼的具體編碼模式感興趣的讀者可以在參考文獻中自行了解。 ASCII#ASCII,全稱American Standard Code for Information Interchange(美國信息交換標準代碼),于 1963 年發布。標準 ASCII 采用 7 位二進制數來表示字符,因此它最多只能表示 128 個字符。? 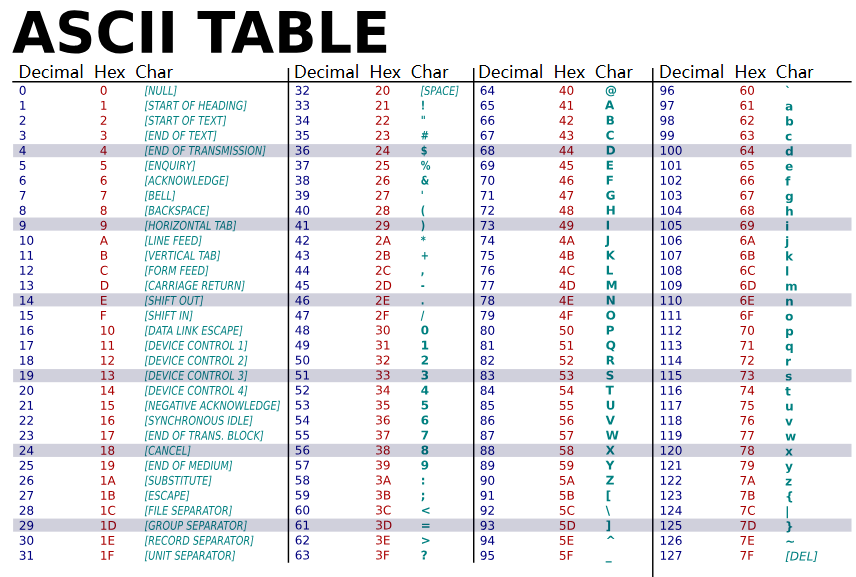 ASCII 編碼雖然解決了英語的編碼問題,但中文怎么辦呢?漢字有那么多字。此時,就有了 GK2312 編碼。 GB2312GB2312,又稱 GB/T 2312-1980,全稱《信息交換用漢字編碼字符集·基本集》,與 1980 年由中國國家標準總局發布。GB2312 收錄共收錄 6763 個漢字,其中一級漢字3755個,二級漢字3008個;同時收錄了包括拉丁字母、希臘字母、日文平假名及片假名字母、注音符號、俄語西里爾字母在內的682個字符。 GB2312 使用兩個字節來表示,第一個字節稱為“高位字節”,對應分區的編號(把區位碼的“區碼”加上特定值);第二個字節稱為“低位字節”,對應區段內的個別碼位(把區位碼的“位碼”加上特定值)。
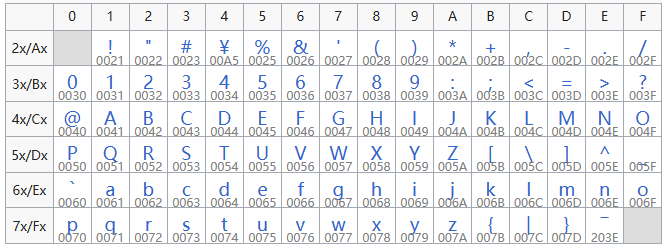
Unicode隨著計算機技術在全世界的廣泛應用,越來越多來自不同地區,擁有不同文字的人們也加入了計算機世界,同時也帶來了越來越多的種類。在 1991 年,由一個非盈利機構 Unicode 聯盟首次發布了 The Unicode Standard,旨在統一整個計算機世界的編碼。 Unicode 的編碼空間從 具體編碼方式可以參考:徹底弄懂 Unicode 編碼 GBK由于 GB2312 只收錄了 6763 個漢字,有一些 GB2312 推出之后才簡化的漢字,部分人用名字、繁體字等未被收錄進標準,由中華人民共和國全國信息技術標準化技術委員會1995年12月1日制訂了 GBK 編碼。GBK 共收錄 21886 個漢字和圖形符號。 UTF-8、UTF-16、UTF-32Unicode 轉換格式(Unicode Transformation Format,簡稱 UTF),一個字符的 Unicode 編碼雖然是確定的,但是由于不同系統平臺的設計不一定一致,以及出于節省空間的目的,對 Unicode 編碼的實現方式有所不同。所以就有著不同的 Unicode 轉換格式:UTF-8、UTF-16、UTF-32。 UTF-8UTF-8(8-bit Unicode Transformation Format)是一種用于實現Unicode的編碼方式,它使用一到四個字節來表示一個字符。UTF-8具有良好的兼容性和效率,能夠與ASCII字符集完全兼容,對于其他語言字符也能夠以較高效的方式進行編碼。 UTF-8 采用下面的規則來編碼
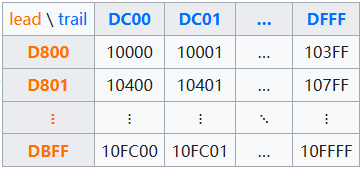
UTF-8 BOMBOM,全稱字節序標志(byte-order mark)。目的是為了表示 Unicode 編碼的字節順序。使用 BOM 模式會在文件頭處添加 字節序(Endianness)是指多字節數據(如一個整數或一個字符的多字節表示)在內存中的存儲順序。而對于 UTF-8 中,每個使用UTF-8存儲的字符,除了第一個字節外,其余字節的頭兩個比特都是以"10"開始,除了第一個字符以外,其他都是唯一的。 但是 Unicode 標準并不要求也不推薦使用 BOM 來表示 UTF-8,但是某些軟件如果第一個字符不是 BOM (或者文件里只包含 ASCII),則拒絕正確解釋 UTF-8。 UTF-16UTF-16 把 Unicode 字符集的抽象碼位映射為 16 位長的整數(即碼元)的序列,也就是說在 UTF-16 編碼方式下,一個 Unicode 字符,需要一個或者兩個 16 位長的碼元來表示。因此 UTF-16 也是一種具體編碼。 Unicode 的基本多語言平面(BMP)內,從U+D800到U+DFFF之間的碼位區段是永久保留不映射到Unicode字符。UTF-16就利用保留下來的0xD800-0xDFFF區塊的碼位來對輔助平面的字符的碼位進行編碼。 UTF-16 采用下面的方法用來編碼:
同樣我們也以“漢”字為例,它在 Unicode 中為:U+6C49,處于 BMP 中,所以直接用 0x6C49 表示。而另外一個以U+10437編碼(??)為例:
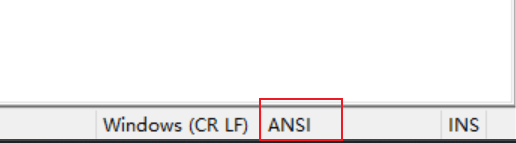
UTF-32#Unicode-32 直接采用 4 個字節來存儲 Unicode 碼位。這種編碼格式的優點是能夠直接用 Unicode 碼位來索引,但同時,相比于其他編碼(UTF-8、UTF-16),浪費空間,所以應用并不廣泛。 ANSI#當我們創建一個文本文件,并用 Notepad++查看其默認編碼時,會看到一個 ANSI
那么 ANSI 是什么編碼呢?簡而言之,ANSI 不是某一種特定的字符編碼,而是在不同系統中,表示不同的編碼。 輸入字符集與執行字符集
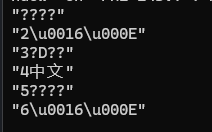
例如:輸入字符集為GB2312時,"中文"兩個字,對應的二進制是:
而輸入字符集為UTF-8時則為下面:
而執行字符集,可以通過顯示設置字符集來修改: 在編譯器中顯式設置輸入字符集和執行字符集。對于GCC編譯器,可以使用 如果輸入字符集和執行字符集不一致,編譯器需要在編譯過程中進行字符編碼的轉換。當兩者不一致時,編譯器需進行編碼轉換,可能引發:
所以,盡量將兩個字符集設置成一樣的。 代碼頁在計算機發展的早期階段,ASCII編碼(美國信息交換標準代碼)是主流的字符編碼方式,它使用7位二進制數表示128個字符,包括英文字母、數字和一些標點符號。然而,ASCII編碼無法滿足多語言環境的需求,因為世界上有成千上萬種語言和符號。 為了解決這個問題,操作系統和軟件開發商引入了代碼頁的概念。代碼頁允許系統支持多種字符集,尤其是那些超出ASCII范圍的語言字符。在Windows操作系統中,代碼頁是系統用來處理文本數據的機制。例如,當用戶在系統中輸入或顯示文本時,系統會根據當前的代碼頁設置來解釋這些字符。 假設你有一個文本文件,內容是中文字符“你好”。如果這個文件是用GBK編碼保存的,那么它的字節序列可能是 再探亂碼看到這里,相信各位讀者對字符編碼已經有些一些基礎的了解。所以,下面讓我們嘗試解答剛開始提出的問題:
為什么控制臺會輸出亂碼?假設有這樣一段代碼: 運行起來后,會發現輸出到控制臺是這種情況:
這個問題的影響因素有兩個:
首先,在 Windows 下,控制臺的默認編碼是當前系統的代碼頁(通常是 GB2312),所以如果你輸出到控制臺的字符不是當前代碼頁編碼對應的字符,那么就會發生亂碼。當前系統的代碼頁通過 cmd 執行命令
當我們輸出到控制臺時,按照 GB2312 編碼去解析這 6 個字節時,我們會得到: 涓(E4B8)(ADE6)枃(9687),其中 ADE6 在 GB2312 中為錯誤編碼,所以會顯示一個問號。 根據這個思路,我們有兩種方法解決這個問題:
第一種我們通過執行 第二種,就是修改文件的字符編碼格式,改成 GB2312。怎么改我就不贅述了,網上一大把。 該字符在當前源字符集中無效?這一個問題與輸入字符集有關,當文件編碼與編譯器預期不一致,例如你的文件是GB2312編碼,但編譯器(如MSVC)默認使用UTF-8(代碼頁65001)來解析源文件。GB2312和UTF-8是不兼容的編碼格式,導致編譯器無法正確解析文件中的字符。 筆者的 Visual Studio 工程命令行有一個
雖然第二個字節符合 10xxxxxx 的格式,但第一個字節的值 QString 一些字符相關的函數在 QString 中有許多的轉換函數:
QString 是以 UTF-16 的格式存儲的字符:
所以,調用上面這些函數就是用指定的格式讀取字符,并將這些字符轉換成 UTF-16 格式。參看下面的例子: 輸入字符集為GB2312時:
輸入字符集為UTF-8時:
最后的最后#感謝各位讀者閱讀本博客,本博客內容在創作過程中,參考了大量百科知識以及其他優秀博客,并結合筆者自身在實際工作中遇到的相關問題。筆者希望通過這篇博客,能為各位讀者在字符編碼這一塊提供一些有價值的見解和幫助。 轉自https://www.cnblogs.com/codegb/p/18768600 該文章在 2025/3/14 9:53:11 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886