【Web開發】萬字長文:GET 和 POST 到底有什么區別?
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
最近在一次初級前端的面試中,問到了這個問題:“你覺得 GET 和 POST 到底有什么區別?”,候選人是這么回答:”get是從服務器上獲取數據,post是向服務器傳送數據“。 這個回答應該和很多讀者心目中的答案一致,但實際上不準確。 這個問題看上去很初級,但實際上涉及到的技術點還是挺多的。今天就來給大家分享一篇文章,給大家展開講講,爭取讓大家徹底弄懂。 HTTP最早被用來做瀏覽器與服務器之間交互HTML和表單的通訊協議;后來又被被廣泛的擴充到接口格式的定義上。 所以在討論GET和POST區別的時候,需要現確定下到底是瀏覽器使用的GET/POST還是用HTTP作為接口傳輸協議的場景。 瀏覽器的GET和POST這里特指瀏覽器中非Ajax的HTTP請求,即從HTML和瀏覽器誕生就一直使用的HTTP協議中的GET/POST。瀏覽器用GET請求來獲取一個html頁面/圖片/css/js等資源;用POST來提交一個 瀏覽器將GET和POST定義為: GET “讀取“一個資源。比如Get到一個html文件。反復讀取不應該對訪問的數據有副作用。比如”GET一下,用戶就下單了,返回訂單已受理“,這是不可接受的。沒有副作用被稱為“冪等“(Idempotent)。 因為GET因為是讀取,就可以對GET請求的數據做緩存。這個緩存可以做到瀏覽器本身上(徹底避免瀏覽器發請求),也可以做到代理上(如nginx),或者做到server端(用Etag,至少可以減少帶寬消耗) POST 在頁面里 不冪等也就意味著不能隨意多次執行,因此也就不能緩存。 比如通過POST下一個單,服務器創建了新的訂單,然后返回訂單成功的界面。這個頁面不能被緩存。試想一下,如果POST請求被瀏覽器緩存了,那么下單請求就可以不向服務器發請求,而直接返回本地緩存的“下單成功界面”,卻又沒有真的在服務器下單,那是一件多么滑稽的事情。 因為POST可能有副作用,所以瀏覽器實現為不能把POST請求保存為書簽。想想,如果點一下書簽就下一個單,是不是很恐怖?。 此外如果嘗試重新執行POST請求,瀏覽器也會彈一個框提示下這個刷新可能會有副作用,詢問要不要繼續。 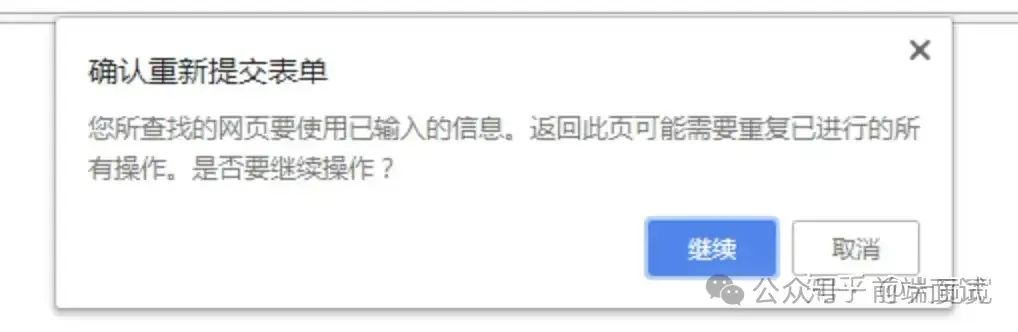 當然,服務器的開發者完全可以把GET實現為有副作用;把POST實現為沒有副作用。 只不過這和瀏覽器的預期不符。把GET實現為有副作用是個很可怕的事情。我依稀記得很久之前百度貼吧有一個因為使用GET請求可以修改管理員的權限而造成的安全漏洞。反過來,把沒有副作用的請求用POST實現,瀏覽器該彈框還是會彈框,對用戶體驗好處改善不大。 但是后邊可以看到,將HTTP POST作為接口的形式使用時,就沒有這種彈框了。 于是把一個POST請求實現為冪等就有實際的意義:POST冪等能讓很多業務的前后端交互更順暢,以及避免一些因為前端bug,觸控失誤等帶來的重復提交。將一個有副作用的操作實現為冪等必須得從業務上能定義出怎么就算是“重復”。如提交數據中增加一個 GET和POST攜帶數據的格式也有區別。 當瀏覽器發出一個GET請求時,就意味著要么是用戶自己在瀏覽器的地址欄輸入,要不就是點擊了 瀏覽器的POST請求都來自表單提交。每次提交,表單的數據被瀏覽器用編碼到HTTP請求的body里。 瀏覽器發出的POST請求的body主要有有兩種格式:
采用后者是因為 瀏覽器在POST一個表單時,url上也可以帶參數,只要 因此我們一般會泛泛的說“GET請求沒有body,只有url,請求數據放在url的querystring中;POST請求的數據在body中“。但這種情況僅限于瀏覽器發請求的場景。 接口中的GET和POST這里是指通過瀏覽器的Ajax api,或者 iOS/Android App 的 此時GET/POST不光能用在前端和后端的交互中,還能用在后端各個子服務的調用中(即當一種RPC協議使用)。 盡管RPC有很多協議,比如thrift,grpc,但是http本身已經有大量的現成的支持工具可以使用,并且對人類很友好,容易debug。HTTP協議在微服務中的使用是相當普遍的。 當用HTTP實現接口發送請求時,就沒有瀏覽器中那么多限制了,只要是符合HTTP格式的就可以發。HTTP請求的格式,大概是這樣的一個字符串(為了美觀,我在\r\n后都換行一下): 其中的“ 從協議本身看,并沒有什么限制說GET一定不能沒有body,POST就一定不能把參放到 因此其實可以更加自由的去利用格式。 比如 當然,太自由也帶來了另一種麻煩,開發人員不得不每次討論確定參數是放url的path里,querystring里,body里,header里這種問題,太低效了。 于是就有了一些列接口規范/風格。其中名氣最大的當屬REST。 REST充分運用GET、POST、PUT和DELETE,約定了這4個接口分別獲取、創建、替換和刪除“資源”,REST最佳實踐還推薦在請求體使用json格式。 這樣僅僅通過看HTTP的method就可以明白接口是什么意思,并且解析格式也得到了統一。
REST中GET和POST不是隨便用的。 在REST中, 【GET】 + 【資源定位符】被專用于獲取資源或者資源列表,比如: 與瀏覽器的場景類似,REST GET也不應該有副作用,于是可以被反復無腦調用。瀏覽器(包括瀏覽器的Ajax請求)對于這種GET也可以實現緩存(如果服務器端提示了明確需要Caching);但是如果用非瀏覽器,有沒有緩存完全看客戶端的實現了。當然,也可以從整個App角度,也可以完全繞開瀏覽器的緩存機制,實現一套業務定制的緩存框架。  REST 【POST】+ 【資源定位符】則用于“創建一個資源”,比如: 這里你就能留意到瀏覽器中用來實現表單提交的POST,和REST里實現創建資源的POST語義上的不同。
服務器應該先根據請求提供的id進行查找,如果存在一個對應id的元素,就用請求中的數據整體替換已經存在的資源;如果沒有,就用“把這個id對應的資源從【空】替換為【請求數據】“。直觀看起來就是“創建”了。 與PUT相比,POST更像是一個“factory”,通過一組必要的數據創建出完整的資源。 有點跑題,就此打住。  回到接口這個主題,上面僅僅粗略介紹了REST的情況。但是現實中總是有REST的變體,也可能用非REST的協議(比如JSON-RPC、SOAP等),每種情況中的GET和POST又會有所不同。 關于安全性我們常聽到GET不如POST安全,因為POST用body傳輸數據,而GET用url傳輸,更加容易看到。但是從攻擊的角度,無論是GET還是POST都不夠安全,因為HTTP本身是明文協議。每個HTTP請求和返回的每個byte都會在網絡上明文傳播,不管是url,header還是body。這完全不是一個“是否容易在瀏覽器地址欄上看到“的問題。 為了避免傳輸中數據被竊取,必須做從客戶端到服務器的端端加密。業界的通行做法就是https——即用SSL協議協商出的密鑰加密明文的http數據。這個加密的協議和HTTP協議本身相互獨立。如果是利用HTTP開發公網的站點/App,要保證安全,https是最最基本的要求。
回到HTTP本身,的確GET請求的參數更傾向于放在url上,因此有更多機會被泄漏。比如攜帶私密信息的url會展示在地址欄上,還可以分享給第三方,就非常不安全了。此外,從客戶端到服務器端,有大量的中間節點,包括網關,代理等。他們的access log通常會輸出完整的url,比如nginx的默認access log就是如此。如果url上攜帶敏感數據,就會被記錄下來。但請注意,就算私密數據在body里,也是可以被記錄下來的,因此如果請求要經過不信任的公網,避免泄密的唯一手段就是https。這里說的“避免access log泄漏“僅僅是指避免可信區域中的http代理的默認行為帶來的安全隱患。比如你是不太希望讓自己公司的運維同學從公司主網關的log里看到用戶的密碼吧。 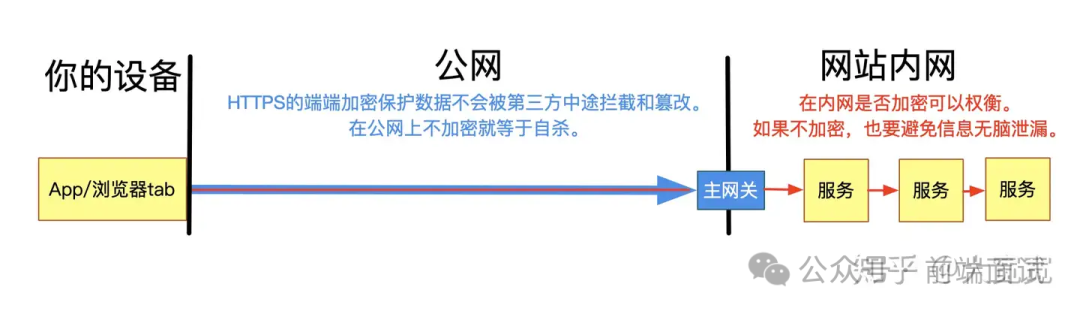 另外,上面講過,如果是用作接口,GET實際上也可以帶body,POST也可以在url上攜帶數據。所以實際上到底怎么傳輸私密數據,要看具體場景具體分析。當然,絕大多數場景,用POST + body里寫私密數據是合理的選擇。一個典型的例子就是“登錄”: 安全是一個巨大的主題,有由很多細節組成的一個完備體系,比如返回私密數據的mask,XSS,CSRF,跨域安全,前端加密,釣魚,salt,…… POST和GET在安全這件事上僅僅是個小角色。因此單獨討論POST和GET本身哪個更安全意義并不是太大。只要記得一般情況下,私密數據傳輸用POST + body就好。 關于編碼常見的說法有,比如GET的參數只能支持ASCII,而POST能支持任意binary,包括中文。但其實從上面可以看到,GET和POST實際上都能用url和body。因此所謂編碼確切地說應該是http中url用什么編碼,body用什么編碼。 先說下url。url只能支持ASCII的說法源自于
實際上這里規定的僅僅是一個ASCII的子集 那這個“編碼”是什么呢?如果有了特殊符號和中文怎么辦呢?一種叫做percent encoding的編碼方法就是干這個用的。 這也就是為啥我們偶爾看到url里有一坨%和16位數字組成的序列。 使用Percent Encoding,即使是binary data,也是可以通過編碼后放在URL上的。 但要特別注意,這個編碼方式只管把字符轉換成URL可用字符,但是卻不管字符集編碼(比如中文到底是用UTF8還是GBK)這塊早期一直都相當亂,也沒有什么統一規范。比如有時跟網頁編碼一樣,有的是操作系統的編碼一樣。最要命的是瀏覽器的地址欄是不受開發者控制的。這樣,對于同樣一個帶中文的url,如果有的瀏覽器一定要用GBK(比如老的IE8),有的一定要用UTF8(比如chrome)。后端就可能認不出來。對此常用的辦法是避免讓用戶輸入這種帶中文的url。如果有這種形式的請求,都改成用戶界面上輸入,然后通過Ajax發出的辦法。Ajax發出的編碼形式開發者是可以100%控制的。
再討論下Body。 HTTP Body相對好些,因為有個Content-Type來比較明確的定義。比如: 這里Content-Type會同時定義請求body的格式(application/x-www-form-urlencoded)和字符編碼(UTF-8)。 所以body和url都可以提交中文數據給后端,但是POST的規范好一些,相對不容易出錯,容易讓開發者安心。對于GET+url的情況,只要不涉及到在老舊瀏覽器的地址欄輸入url,也不會有什么太大的問題。 回到POST,瀏覽器直接發出的POST請求就是表單提交,而表單提交只有application/x-www-form-urlencoded針對簡單的key-value場景;和multipart/form-data,針對只有文件提交,或者同時有文件和key-value的混合提交表單的場景。 如果是Ajax或者其他HTTP Client發出去的POST請求,其body格式就非常自由了,常用的有json,xml,文本,csv……甚至是你自己發明的格式。只要前后端能約定好即可。 瀏覽器的POST需要發兩個請求嗎?上文中的"HTTP 格式“清楚的顯示了HTTP請求可以被大致分為“請求頭”和“請求體”兩個部分。使用HTTP時大家會有一個約定,即所有的“控制類”信息應該放在請求頭中,具體的數據放在請求體里“。于是服務器端在解析時,總是會先完全解析全部的請求頭部。這樣,服務器端總是希望能夠了解請求的控制信息后,就能決定這個請求怎么進一步處理,是拒絕,還是根據content-type去調用相應的解析器處理數據,或者直接用zero copy轉發。 比如在用Java寫服務時,請求處理代碼總是能從HttpSerlvetRequest里getParameter/Header/url。這些信息都是請求頭里的,框架直接就解析了。而對于請求體,只提供了一個inputstream,如果開發人員覺得應該進一步處理,就自己去讀取和解析請求體。這就能體現出服務器端對請求頭和請求體的不同處理方式。 舉個實際的例子,比如寫一個上傳文件的服務,請求url中包含了文件名稱,請求體中是個尺寸為幾百兆的壓縮二進制流。服務器端接收到請求后,就可以先拿到請求頭部,查看用戶是不是有權限上傳,文件名是不是符合規范等。如果不符合,就不再處理請求體的數據了,直接丟棄。而不用等到整個請求都處理完了再拒絕。 為了進一步優化,客戶端可以利用HTTP的Continued協議來這樣做:客戶端總是先發送所有請求頭給服務器,讓服務器校驗。如果通過了,服務器回復“100 - Continue”,客戶端再把剩下的數據發給服務器。如果請求被拒了,服務器就回復個400之類的錯誤,這個交互就終止了。這樣,就可以避免浪費帶寬傳請求體。但是代價就是會多一次Round Trip。如果剛好請求體的數據也不多,那么一次性全部發給服務器可能反而更好。 基于此,客戶端就能做一些優化,比如內部設定一次POST的數據超過1KB就先只發“請求頭”,否則就一次性全發。客戶端甚至還可以做一些Adaptive的策略,統計發送成功率,如果成功率很高,就總是全部發等等。不同瀏覽器,不同的客戶端(curl,postman)可以有各自的不同的方案。不管怎樣做,優化目的總是在提高數據吞吐和降低帶寬浪費上做一個折衷。 因此到底是發一次還是發N次,客戶端可以很靈活的決定。因為不管怎么發都是符合HTTP協議的,因此我們應該視為這種優化是一種實現細節,而不用扯到GET和POST本身的區別上。更不要當個什么世紀大發現。 到底什么算請求體看完了上面的內容后,讀者也許會對“什么是請求體”感到困惑不已,比如 從HTTP協議的角度,“請求頭”就是 但是從業務角度,如果你把一次請求立即為一個調用的話。比如上面的 用Java寫大概等價于 那么這一行函數名和兩個參數都可以看作是一個請求,不區分頭和體。即便用HTTP協議實現,title和author編碼到了HTTP請求體中。Java的 對于HTTP,需要區分【頭】和【體】,Http Request和Http Response都這么區分。Http這么干主要用作:
但從高一級的業務角度,我們在意的其實是【請求】和【返回】。當我們在說“請求頭”這三個字時,也許實際的意思是【請求】。而用HTTP實現【請求】時,可能僅僅用到【HTTP的請求頭】(比如大部分GET請求),也可能是【HTTP請求頭】+【HTTP請求體】(比如用POST實現一次下單)。 總之,這里有兩層,不要混哦。 關于URL的長度因為上面提到了不論是GET和POST都可以使用URL傳遞數據,所以我們常說的“GET數據有長度限制“其實是指”URL的長度限制“。 HTTP協議本身對URL長度并沒有做任何規定。實際的限制是由客戶端/瀏覽器以及服務器端決定的。 先說瀏覽器。不同瀏覽器不太一樣。比如我們常說的2048個字符的限制,其實是IE8的限制。并且原始文檔的說的其實是“URL的最大長度是2083個字符,path的部分最長是2048個字符“。見https://support.microsoft.com/en-us/help/208427/maximum-url-length-is-2-083-characters-in-internet-explorer。IE8之后的IE URL限制我沒有查到明確的文檔,但有些資料稱IE 11的地址欄只能輸入法2047個字符,但是允許用戶點擊html里的超長URL。我沒實驗,哪位有興趣可以試試。  Chrome的URL限制是2MB,見https://chromium.googlesource.com/chromium/src/+/master/docs/security/url_display_guidelines/url_display_guidelines.md  Safari,Firefox等瀏覽器也有自己的限制,但都比IE大的多,這里就不挨個列出了。 然而新的IE已經開始使用Chrome的內核了,也就意味著“瀏覽器端URL的長度限制為2048字符”這種說法會慢慢成為歷史。 其他的客戶端,比如Java的,js的http client大多數也并沒有限制URL最大有多長。 除了瀏覽器,服務器這邊也有限制,比如apache的LimieRequestLine指令。 apache實際上限制的是HTTP請求第一行“Request Line“的長度,即 ?再比如nginx用 Tomcat的限制是web.xml里maxHttpHeaderSize來設置的,控制的是整個“請求頭”的總長度。 為啥要限制呢?如果寫過解析一段字符串的代碼就能明白,解析的時候要分配內存。對于一個字節流的解析,必須分配buffer來保存所有要存儲的數據。而URL這種東西必須當作一個整體看待,無法一塊一塊處理,于是就處理一個請求時必須分配一整塊足夠大的內存。如果URL太長,而并發又很高,就容易擠爆服務器的內存;同時,超長URL的好處并不多,我也只有處理老系統的URL時因為不敢碰原來的邏輯,又得追加更多數據,才會使用超長URL。 對于開發者來說,使用超長的URL完全是給自己埋坑,需要同時要考慮前后端,以及中間代理每一個環節的配置。此外,超長URL會影響搜索引擎的爬蟲,有些爬蟲甚至無法處理超過2000個字節的URL。這也就意味著這些URL無法被搜到,坑爹啊。 其實并沒有太大必要弄清楚精確的URL最大長度限制。我個人的經驗是,只要某個要開發的資源/api的URL長度有可能達到2000個bytes以上,就必須使用body來傳輸數據,除非有特殊情況。至于到底是GET + body還是POST + body可以看情況決定。
總結上面講了一大堆,是希望讀者不要死記硬背GET和POST的區別,而是能從更廣的層面去看待和思考這個問題。 最后,協議都是人定的。只要客戶端和服務器能彼此認同,就能工作。在常規的情況下,用符合規范的方式去實現系統可以減少很多工作量——大家都約定好了,就不要折騰了。但是,總會有一些情況用常規規范不合適,不滿足需求。這時思路也不能被規范限制死,更不要死摳RFC。這些規范也許不能處理你遇到的特殊問題。比如:
協議是死的,人是活的。遇到實際的問題時靈活的運用手上的工具滿足需求就好。 最后
該文章在 2025/3/6 11:15:37 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886


