百萬級群聊的設計實踐
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
本文介紹了服務端在搭建 Web 版的百萬人級別的群聊系統時,遇到的技術挑戰和解決思路,內容包括:通信方案選型、消息存儲、消息有序性、消息可靠性、未讀數統計。
一、引言現在IM群聊產品多種多樣,有國民級的微信、QQ,企業級的釘釘、飛書,還有許多公司內部的IM工具,這些都是以客戶端為主要載體,而且群聊人數通常都是有限制,微信正常群人數上限是500,QQ2000人,收費能達到3000人,這里固然有產品考量,但技術成本、資源成本也是很大的因素。而筆者業務場景上需要一個迭代更新快、輕量級(不依賴客戶端)、單群百萬群成員的純H5的IM產品,本文將回顧實現一個百萬人量級的群聊,服務器側需要考慮的設計要點,希望可以給到讀者一些啟發。
二、背景介紹不同的群聊產品,采用的技術方案是不同的,為了理解接下來的技術選型,需要先了解下這群聊產品的特性。
三、通信技術即時通信常見的通信技術有短輪詢、長輪詢、Server-Sent Events(SSE)、Websocket。短輪詢和長輪詢適用于實時性要求不高的場景,比如論壇的消息提醒。SSE 適用于服務器向客戶端單向推送的場景,如實時新聞、股票行情。Websocket 適用于實時雙向通信的場景,實時性好,且服務端、前端都有比較成熟的三方包,如 socket.io,所以這塊在方案選擇中是比較 easy 的,前后端使用 Websocket 來實現實時通信。
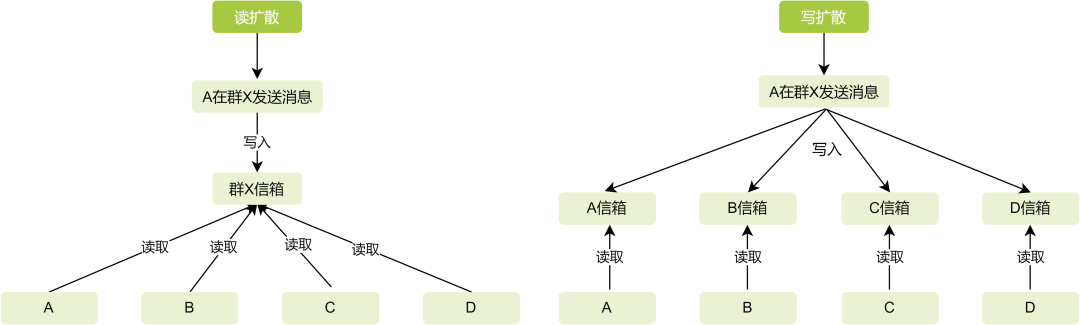
四、消息存儲群聊消息的保存方式,主流有2種方式:讀擴散、寫擴散。圖1展示了它們的區別,區別就在于消息是寫一次還是寫N次,以及如何讀取。
圖1
讀擴散就是所有群成員共用一個群信箱,當一個群產生一條消息時,只需要寫入這個群的信箱即可,所有群成員從這一個信箱里讀取群消息。 優點是寫入邏輯簡單,存儲成本低,寫入效率高。缺點是讀取邏輯相對復雜,要通過消息表與其他業務表數據聚合;消息定制化處理復雜,需要額外的業務表;可能還有IO熱點問題。
舉個例子: 很常見的場景,展示用戶對消息的已讀未讀狀態,這個時候公共群信箱就無法滿足要求,必須增加消息已讀未讀表來記錄相關狀態。還有用戶對某條消息的刪除狀態,用戶可以選擇刪除一條消息,但是其他人仍然可以看到它,此時也不適合在公共群信箱里拓展,也需要用到另一張關系表,總而言之針對消息做用戶特定功能時就會比寫擴散復雜。 寫擴散就是每個群成員擁有獨立的信箱,每產生一條消息,需要寫入所有群成員信箱,群成員各自從自己的信箱內讀取群消息。優點是讀取邏輯簡單,適合消息定制化處理,不存在IO熱點問題。缺點是寫入效率低,且隨著群成員數增加,效率降低;存儲成本大。
所以當單群成員在萬級以上時,用寫擴散就明顯不太合適了,寫入效率太低,而且可能存在很多無效寫入,不活躍的群成員也必須得有信箱,存儲成本是非常大的,因此采用讀擴散是比較合適的。
據了解,微信是采用寫擴散模式,微信群設定是500人上限,寫擴散的缺點影響就比較小。
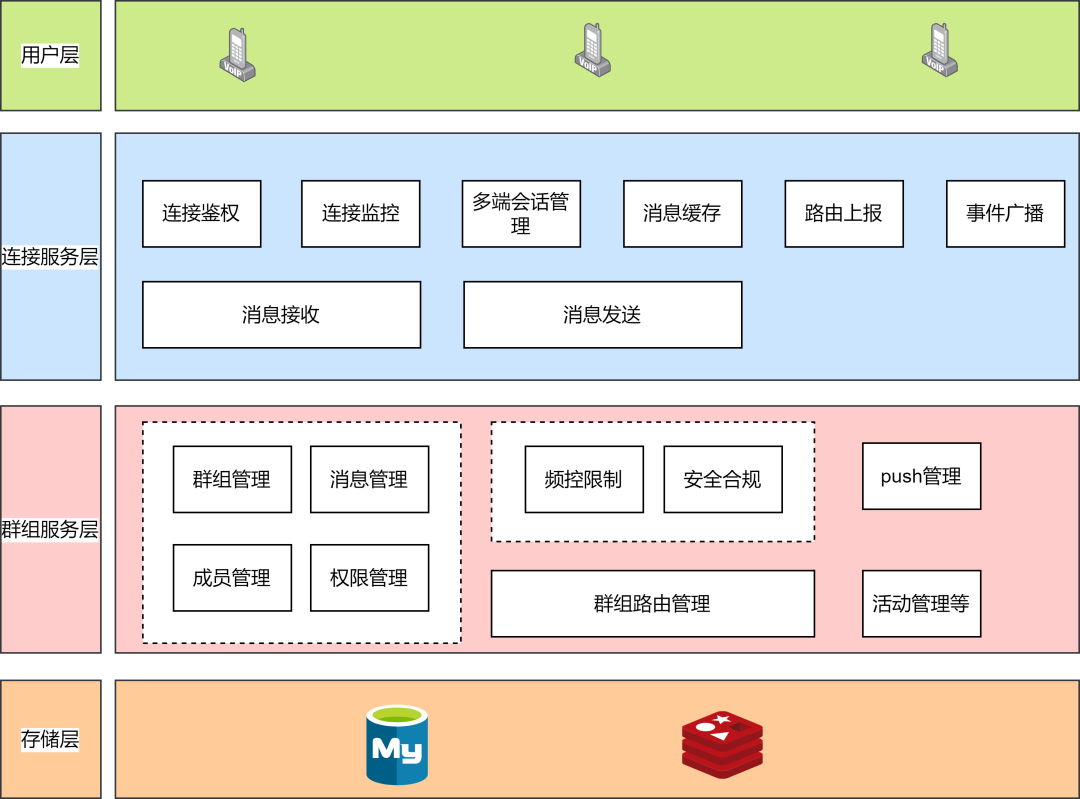
五、架構設計5.1 整體架構先來看看群聊的架構設計圖,如圖2所示:
圖2
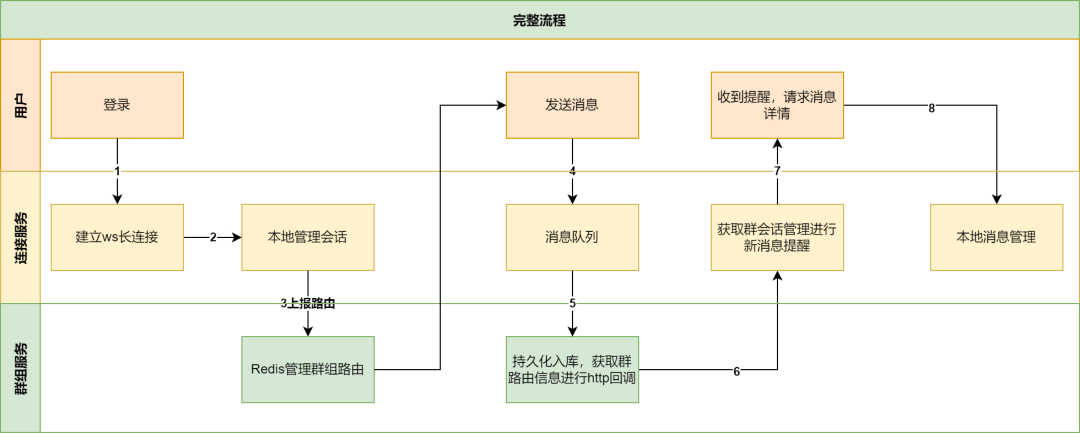
從用戶登錄到發送消息,再到群用戶收到這條消息的系統流程如圖3所示:
圖3
5.2 路由策略用戶應該連接到哪一臺連接服務呢?這個過程重點考慮如下2個問題:
保證均衡有如下幾個算法:
5.3 重連機制當應用在擴縮容或重啟升級時,在該節點上的客戶端怎么處理?由于設計有心跳機制,當心跳不通或監聽連接斷開時,就認為該節點有問題了,就嘗試重新連接;如果客戶端正在發送消息,那么就需要將消息臨時保存住,等待重新連接上后再次發送。
5.4 線程策略將連接服務里的IO線程與業務線程隔離,提升整體性能,原因如下:
5.5 有狀態鏈接在這樣的場景中不像 HTTP 那樣是無狀態的,需要明確知道各個客戶端和連接的關系。比如需要向客戶端廣播群消息時,首先得知道客戶端的連接會話保存在哪個連接服務節點上,自然這里需要引入第三方中間件來存儲這個關系。通過由連接服務主動上報給群組服務來實現,上報時機是客戶端接入和斷開連接服務以及周期性的定時任務。
5.6 群組路由設想這樣一個場景:需要給群所有成員推送一條消息怎么做?通過群編號去前面的路由 Redis 獲取對應群的連接服務組,再通過 HTTP 方式調用連接服務,通過連接服務上的長連接會話進行真正的消息下發。
5.7 消息流轉連接服務直接接收用戶的上行消息,考慮到消息量可能非常大,在連接服務里做業務顯然不合適,這里完全可以選擇 Kafka 來解耦,將所有的上行消息直接丟到 Kafka 就不管了,消息由群組服務來處理。
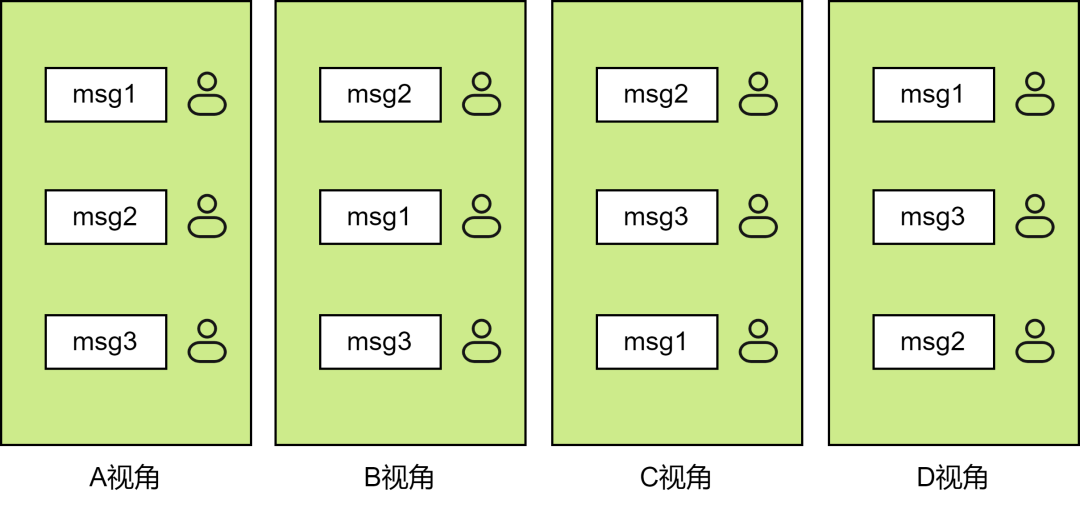
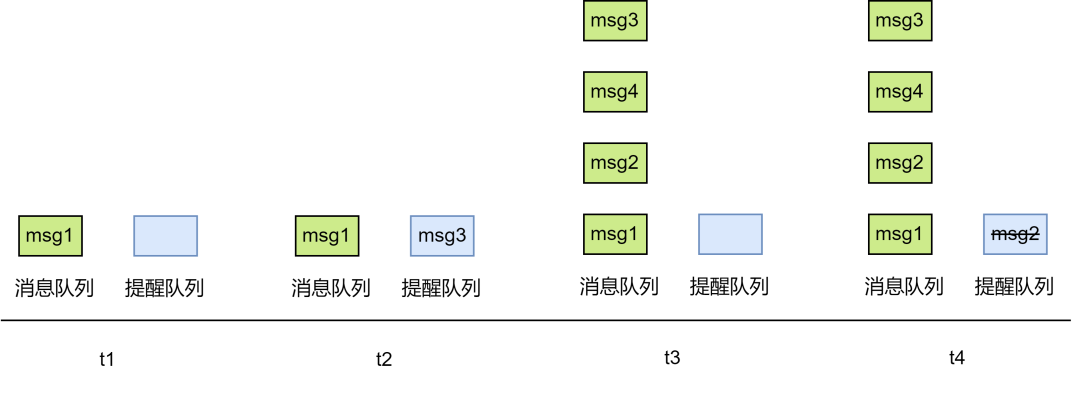
六、消息順序?6.1 亂序現象 為什么要講消息順序,來看一個場景。假設群里有用戶A、用戶B、用戶C、用戶D,下面以 ABCD 代替,假設A發送了3條消息,順序分別是 msg1、msg2、msg3,但B、C、D看到的消息順序不一致,如圖4所示:
圖4
這時B、C、D肯定會覺得A在胡言亂語了,這樣的產品用戶必定是不喜歡的,因此必須要保證所有接收方看到的消息展示順序是一致的。
6.2 原因分析所以先了解下消息發送的宏觀過程:
在上面的過程中,都可能產生順序問題,簡要分析幾點原因:
6.3 解決方案6.3.1 單用戶保持有序通過上面的分析可以知道,其實無法保證或是無法衡量不同用戶之間的消息順序,那么只需保證同一個用戶的消息是有序的,保證上下文語義,所以可以得出一個比較樸素的實現方式:以服務端數據庫的唯一自增ID為標尺來衡量消息的時序,然后讓同一個用戶的消息處理串行化。那么就可以通過以下幾個技術手段配合來解決:
6.3.2 推拉結合到這里基本解決了同一個用戶的消息可以按照他自己發出的順序入庫的問題,即解決了消息發送流程里第一、二步。
第三、四步存在的問題是這樣的: A發送了 msg1、msg2、msg3,B發送了 msg4、msg5、msg6,最終服務端的入庫順序是msg1、msg2、msg4、msg3、msg5、msg6,那除了A和B其他人的消息順序需要按照入庫順序來展示,而這里的問題是服務端考量推送吞吐量,在推送環節是并發的,即可能 msg4 比 msg1 先推送到用戶端上,如果按照推送順序追加來展示,那么就與預期不符了,每個人看到的消息順序都可能不一致,如果用戶端按照消息的id大小進行比較插入的話,用戶體驗將會比較奇怪,突然會在2個消息中間出現一條消息。所以這里采用推拉結合方式來解決這個問題,具體步驟如下:
圖5
圖6
舉例,圖5表示服務端的消息順序,圖6表示用戶端拉取消息時本地消息隊列和提醒隊列的變化邏輯。
通過推拉結合的方式可以保證所有用戶收到的消息展示順序一致。細心的讀者可能會有疑問,如果聊天信息流里有自己發送的消息,那么可能與其他的人看到的不一致,這是因為自己的消息展示不依賴拉取,需要即時展示,給用戶立刻發送成功的體驗,同時其他人也可能也在發送,最終可能比他先入庫,為了不出現信息流中間插入消息的用戶體驗,只能將他人的新消息追加在自己的消息后面。所以如果作為發送者,消息順序可能不一致,但是作為純接收者,大家的消息順序都是一樣的。
七、消息可靠性在IM系統中,消息的可靠性同樣非常重要,它主要體現在:
7.1 消息不丟失設計
7.2 消息不重復設計
八、未讀數統計為了提醒用戶有新消息,需要給用戶展示新消息提醒標識,產品設計上一般有小紅點、具體的數值2種方式。具體數值比小紅點要復雜,這里分析下具體數值的處理方式,還需要分為初始打開群和已打開群2個場景。
已打開群:可以完全依賴用戶端本地統計,用戶端獲取到新消息后,就將未讀數累計加1,等點進去查看后,清空未讀數統計,這個比較簡單。
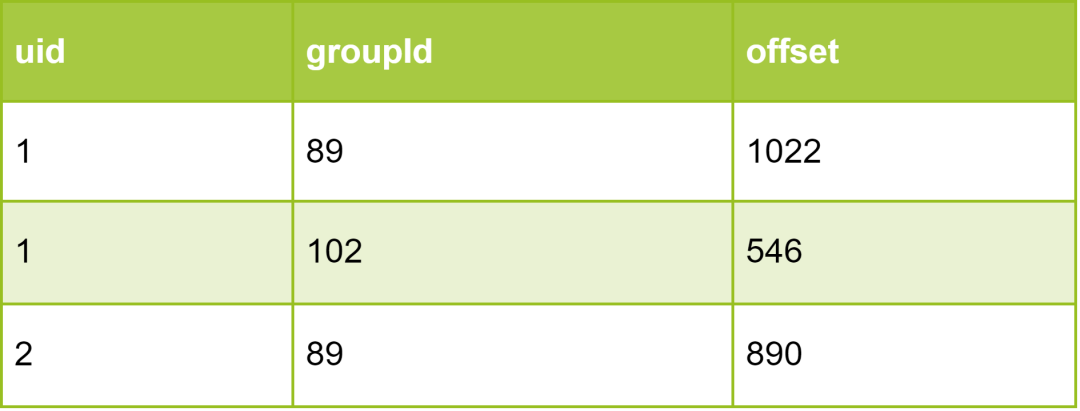
初始打開群:由于用戶端采用H5開發,用戶端沒有緩存,沒有能力緩存最近的已讀消息游標,因此這里完全需要服務端來統計,在打開群時下發最新的聊天信息流和未讀數,下面具體講下這個場景下該怎么設計。 既然由服務端統計未讀數,那么少不了要保存用戶在某個群里已經讀到哪個消息,類似一個游標,用戶已讀消息,游標往前走。用戶已讀消息存儲表設計如圖7所示:
圖7
游標offset采用定時更新策略,連接服務會記錄用戶最近一次拉取到的消息ID,定時異步上報批量用戶到群組服務更新 offset。 該表第一行表示用戶1在 id=89 的群里,最新的已讀消息是id=1022消息,那么可以通過下面的SQL來統計他在這個群里的未讀數:select count(1) from msg_info where groupId = 89 and id > 1022。但是事情并沒這么簡單,一個用戶有很多群,每個群都要展示未讀數,因此要求未讀數統計的程序效率要高,不然用戶體驗就很差,很明顯這個 SQL 的耗時波動很大,取決于 offset 的位置,如果很靠后,SQL 執行時間會非常長。筆者通過2個策略來優化這個場景:
圖8
如上圖8所示,每個群都會構建一個長度為100,score 和 member 都是消息ID,可以通過 zrevrank 命令得到某個 offset 的排名值,該值可以換算成未讀數。比如:用戶1在群89的未讀消息數,'zrevrank 89 1022' = 2,也就是有2條未讀數。用戶2在群89的未讀數,'zrevrank 89 890' = nil,那么未讀數就是99+。同時消息新增、刪除都需要同步維護該數據結構,失效或不存在時從 MySQL 初始化。
九、超大群策略前面提到,設計目標是在同一個群里能支撐百萬人,從架構上可以看到,連接服務處于流量最前端,所以它的承載力直接決定了同時在線用戶的上限。 影響它的因素有:
9.1 消息風暴當同時在線用戶數非常多,例如百萬時,會面臨如下幾個問題:
9.2 消息壓縮如果某一個時刻,推送消息的數量比較大,且群同時在線人數比較多的時候,連接服務層的機房出口帶寬就會成為消息推送的瓶頸。 做個計算,百萬人在線,需要5臺連接服務,一條消息1KB,一般情況下,5臺連接服務集群都是部署在同一個機房,那么這個機房的帶寬就是1000000*1KB=1GB,如果多幾個超大群,那么對機房的帶寬要求就更高,所以如何有效的控制每一個消息的大小、壓縮每一個消息的大小,是需要思考的問題。 經過測試,使用 protobuf 數據交換格式,平均每一個消息可以節省43%的字節大小,可以大大節省機房出口帶寬。
9.3 塊消息超大群里,消息推送的頻率很高,每一條消息推送都需要進行一次IO系統調用,顯然會影響服務器性能,可以采用將多個消息進行合并推送。 主要思路:以群為維度,累計一段時間內的消息,如果達到閾值,就立刻合并推送,否則就以勻速的時間間隔將在這個時間段內新增的消息進行推送。 時間間隔是1秒,閾值是10,如果500毫秒內新增了10條消息,就合并推送這10條消息,時間周期重置;如果1秒內只新增了8條消息,那么1秒后合并推送這8條消息。這樣做的好處如下:
十、總結在本文中,筆者介紹了從零開始搭建一個生產級百萬級群聊的一些關鍵要點和實踐經驗,包括通信方案選型、消息存儲、消息順序、消息可靠性、高并發等方面,但仍有許多技術設計未涉及,比如冷熱群、高低消息通道會放在未來的規劃里。IM開發業界沒有統一的標準,不同的產品有適合自己的技術方案,希望本文能夠帶給讀者更好地理解和應用這些技術實踐,為構建高性能、高可靠性的群聊系統提供一定的參考。 轉自https://www.cnblogs.com/vivotech/p/18740478 該文章在 2025/3/5 11:18:40 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886