拯救SQL Server數據庫事務日志文件損壞的終極大招
當前位置:點晴教程→知識管理交流
→『 技術文檔交流 』
在數據庫的日常管理中,我們不可避免的會遇到服務器突然斷電(沒有進行電源冗余),服務器故障或者 SQL Server 服務突然停掉, 頭大的是ldf事務日志文件也損毀了,SQL Server服務器起來之后,發現數據庫處于"Recovery Pending" 狀態。 更麻煩的是該數據庫沒有任何備份或者備份已經比較久遠; 當然這些都不是最難的,最難的是連資深DBA使出ATTACH_REBUILD_LOG和 DBCC CEHECKDB 的 REPAIR_ALLOW_DATA_LOSS 選項等招數時候, 即使已經做好了最壞打算,做了丟失部分數據的準備,數據庫還是無法上線。 本文將分享終極處理方法,幫助您成功恢復數據庫。 測試環境: SQL Server 2022,Windows 2016 注意:奇技淫巧有風險,做任何操作之前注意先做備份!
模擬環境 首先,在數據庫 testdb 中創建 testObject 表,并不停插入所有對象數據。 在窗口一我們運行插入數據腳本,使用多次 CROSS JOIN,以獲得足夠多的數據,插入數據腳本實際是一個模擬的大事務。 --窗口1 CREATE DATABASE testdb GO USE testdb GO 返回信息如下 -- Msg 109, Level 20, State 0, Line 0 --A transport-level error has occurred when receiving results from the server. (provider: Shared Memory Provider, error: 0 - 管道已結束。)
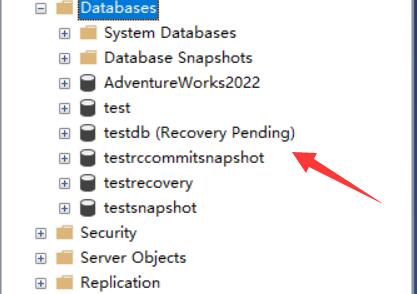
在窗口二我們在關閉測試實例時,窗口一的插入事務仍然在運行。 這將使得數據庫處于不一致狀態,在數據庫啟動時,執行數據庫恢復。 --窗口2 --執行完下面語句之后,移走ldf文件,模擬ldf文件損壞 SHUTDOWN WITH NOWAIT 數據庫停服后,將testdb數據庫 的ldf事務日志文件改名或者移到其他路徑,重新啟動SQL Server 服務,可以看到,testdb 數據庫處于“恢復掛起”狀態。
因為在停服時候,還有未提交的插入事務保存在ldf事務日志文件,需要在數據庫啟動時候把事務日志撈出來做crash recovery。 數據庫啟動之前,已經把ldf事務日志文件移動到別的地方
此時,我們已經有一個孤立的,不一致的數據庫文件。 現在我們必須先離線數據庫,把mdf文件復制到別的地方作為備份,然后刪除數據庫,為后續的附加ldf事務日志文件做準備 --窗口3 USE master GO ALTER DATABASE [testdb] SET OFFLINE; 把mdf文件復制到別的地方作為備份,因為數據庫離線了,并不會刪除物理數據文件 --窗口4 USE master GO DROP DATABASE [testdb] ;
傳統方法 使用 ATTACH_REBUILD_LOG 來重建ldf事務日志文件 --窗口5 USE master GO CREATE DATABASE [testdb] ON (FILENAME='E:\DataBase\testdb.mdf') FOR ATTACH_REBUILD_LOG GO 報錯信息如下 --文件激活失敗。物理文件名稱'E:\DataBase\testdb_log.ldf'可能不正確。 --無法重新生成日志,原因是數據庫關閉時存在打開的事務/用戶,該數據庫沒有檢查點或者該數據庫是只讀的。如果事務日志文件被手動刪除或者由于硬件或環境問題而丟失,則可能出現此錯誤。 --Msg 1813, Level 16, State 2, Line 8 --無法打開新數據庫 'testdb'。CREATE DATABASE 中止。
就算資深DBA老司機也會在這里翻車
新方法 使用 CREATE DATABASE 語句中非官方文檔記載(undocument)的命令,這個命令就是ATTACH_FORCE_REBUILD_LOG 這個命令會強制重建ldf事務日志文件,即使數據庫檢測到ldf事務日志文件和mdf數據文件之間有不一致的情況。 --窗口6 USE master GO CREATE DATABASE [testdb] ON (FILENAME='E:\DataBase\testdb.mdf') FOR ATTACH_FORCE_REBUILD_LOG GO 返回信息如下 --文件激活失敗。物理文件名稱'E:\DataBase\testdb_log.ldf'可能不正確。 --新的日志文件 'E:\DataBase\testdb_log.ldf' 已創建。 數據庫雖然恢復正常,但數據表依然無法訪問 --窗口7 USE [testdb] GO SELECT TOP 10 * FROM [dbo].[testObject] SELECT COUNT(*) FROM [dbo].[testObject] 報錯信息如下 --Msg 824, Level 24, State 2, Line 18 --SQL Server 檢測到基于邏輯一致性的 I/O 錯誤: pageid 不正確(應為 1:69856,但實際為 0:0)。在文件“E:\DataBase\testdb.mdf”中的偏移 0x000000221c0000 處,在數據庫 ID 9 中的頁面 (1:69856) 的 讀取 期間發生。SQL Server 錯誤日志或操作系統錯誤日志中的其他消息可能會提供更多詳細信息。這是一個威脅數據庫完整性的嚴重錯誤條件,必須立即更正。請執行完整的數據庫一致性檢查(DBCC CHECKDB)。此錯誤可以由許多因素導致;有關詳細信息,請參閱 https://go.microsoft.com/fwlink/?linkid=2252374。
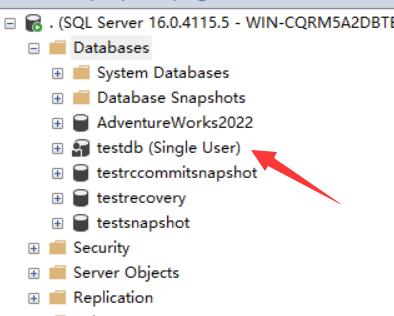
使用最小數據丟失的方式,修復數據庫 頭兩個命令將數據庫分別置于緊急模式和單用戶模式,這是我們執行 DBCC CHECKDB 的 REPAIR_ALLOW_DATA_LOSS 選項的前提。 最后一句命令是將數據庫恢復多用戶模式。 --窗口8 --使用最小數據丟失的方式,修復數據庫 USE [master] GO ALTER DATABASE [testdb] SET EMERGENCY GO ALTER DATABASE [testdb] SET SINGLE_USER WITH NO_WAIT GO DBCC CHECKDB([testdb],REPAIR_ALLOW_DATA_LOSS) WITH ALL_ERRORMSGS --dbcc checkdb執行完畢之后執行下面語句,讓數據庫可以重新訪問 ALTER DATABASE [testdb] SET MULTI_USER WITH NO_WAIT DBCC CHECKDB返回信息如下,很多信息這里做了省略 可以看到有5924 個一致性錯誤,修復了 5924 個一致性錯誤,也就是全部修復了 --testdb的 DBCC 結果。 --Msg 8909, Level 16, State 1, Line 19 --表錯誤: 對象 ID 0,索引 ID -1,分區 ID 0,分配單元 ID 0 (類型為 Unknown),頁 ID (1:69830) 在其頁頭中包含錯誤的頁 ID。頁頭中的 PageId 為 (0:0)。 -- 該錯誤已修復。 --Msg 8909, Level 16, State 1, Line 19 --表錯誤: 對象 ID 0,索引 ID -1,分區 ID 0,分配單元 ID 0 (類型為 Unknown),頁 ID (1:69831) 在其頁頭中包含錯誤的頁 ID。頁頭中的 PageId 為 (0:0)。 -- 該錯誤已修復。 --Msg 8909, Level 16, State 1, Line 19 --data)釋放。 --修復: 頁 (1:70420) 已從對象 ID 1541580530,索引 ID 0,分區 ID 72057594045857792,分配單元 ID 72057594052673536 (類型為 In-row data)釋放。 --修復: 頁 (1:70421) 已從對象 ID 1541580530,索引 ID 0,分區 ID 72057594045857792,分配單元 ID 72057594052673536 (類型為 In-row data)釋放 。。。 --對象 ID 1541580530,索引 ID 0,分區 ID 72057594045857792,分配單元 ID 72057594052673536 (類型為 In-row data): 無法處理頁 (1:69866)。有關詳細信息,請參閱其他錯誤消息。 -- 該錯誤已修復。 --Msg 8928, Level 16, State 1, Line 19 --對象 ID 1541580530,索引 ID 0,分區 ID 72057594045857792,分配單元 ID 72057594052673536 (類型為 In-row data): 無法處理頁 (1:69867)。有關詳細信息,請參閱其他錯誤消息。 -- 該錯誤已修復。 。。。 --sys.filetable_updates_2105058535的 DBCC 結果。 --對象“sys.filetable_updates_2105058535”在 0 頁中找到 0 行。 --CHECKDB 在數據庫 'testdb' 中發現 0 個分配錯誤和 5924 個一致性錯誤。 --CHECKDB 在數據庫 'testdb' 中修復了 0 個分配錯誤和 5924 個一致性錯誤。 --DBCC 執行完畢。如果 DBCC 輸出了錯誤信息,請與系統管理員聯系。 數據庫處于單用戶模式
設置回多用戶模式之后,嘗試查詢數據 --從數據行數來看,具體你是不知道丟失多少數據的,只能說能挽救多少是多少吧 USE [testdb] GO SELECT TOP 10 * FROM [dbo].[testObject] SELECT COUNT(*) AS'rowcount' FROM [dbo].[testObject] 數據是查詢出來了,但是具體丟失多少數據,我們無法掌握 至少數據庫最后一次checkpoint點之后的所有數據將會丟失。
總結 在傳統的方法里面,還有一個方法就是 新建一個同名的空數據庫作為傀儡數據庫,然后替換傀儡數據庫的數據文件 再對傀儡數據庫執行DBCC CEHECKDB 的 REPAIR_ALLOW_DATA_LOSS 選項,但是實際上也不能保證100%有效 這個方法網上已經有相關文章,這里就不展開敘述了。
起初使用ATTACH_REBUILD_LOG來重建ldf事務日志文件不成功,還有打算借助第三方工具ApexSQL Log,不過因為網友的數據庫版本太高 ApexSQL Log工具不支持,幸好在外網剛好搜索到ATTACH_FORCE_REBUILD_LOG這個命令, 最后總算幫這個網友盡最大努力挽回了數據。
DBCC REBUILD_LOG:已經廢棄 轉自https://www.cnblogs.com/lyhabc/p/18306393/ultimate-solution-to-rescue-sql-server-transaction-log-file-corruption 該文章在 2025/2/18 8:49:41 編輯過 |
關鍵字查詢
相關文章
正在查詢... 



|


 400 186 1886
400 186 1886



 ?
?